 Ampliar / No tienes que ser Keir Dullea para saberlo completamente comprender la inteligencia artificial puede ser intimidante. Rinhart / Corbis a través de Getty Images
Ampliar / No tienes que ser Keir Dullea para saberlo completamente comprender la inteligencia artificial puede ser intimidante. Rinhart / Corbis a través de Getty Images
La IA, o inteligencia artificial, es enorme en este momento. “Sin solución” se resuelven problemas, se invierten miles de millones de dólares, y Microsoft incluso contrató a Common para decirle cuán grande es su IA con la palabra hablada poesía. Yikes
Al igual que con cualquier tecnología nueva, puede ser difícil cortar el bombo publicitario Pasé años investigando en robótica y vehículos aéreos no tripulados y “AI”, pero incluso a mí me ha costado mantener el ritmo. En reciente años he pasado mucho tiempo aprendiendo a responder incluso algunas de las preguntas más básicas como:
- �De qué están hablando las personas cuando dicen IA?
- �Cuál es la diferencia entre IA, aprendizaje automático y profundo �aprendizaje?
- �Qué tiene de bueno el aprendizaje profundo?
- �Qué tipo de problemas anteriormente difíciles ahora son fáciles de resolver, �Y qué sigue siendo difícil?
Sé que no estoy solo preguntándome estas cosas. Entonces si tienes me he estado preguntando de qué se trata la emoción de la IA como máximo nivel básico, es hora de echar un vistazo detrás de la cortina. Si eres un experto en IA que lee los documentos de NIPS por diversión, no habrá mucho nuevo para ti aquí, pero todos esperamos tu aclaraciones y correcciones en los comentarios.
�Qué es la IA?
Hay una vieja broma en informática que dice así: �Cuál es la diferencia entre IA y automatización? Bueno, la automatización es lo que podemos hacer con las computadoras, y la IA es lo que deseamos podríamos hacer. Tan pronto como descubrimos cómo hacer algo, se detiene siendo IA y comienza a ser automatización.
Ese chiste existe porque, incluso hoy, la IA no está bien definido: la inteligencia artificial simplemente no es un término técnico. Si si buscabas en Wikipedia, AI es “inteligencia demostrado por máquinas, en contraste con la inteligencia natural exhibido por humanos y otros animales “. Eso es tan vago como puedes obtener.
En general, hay dos tipos de IA: IA fuerte e IA débil. La IA fuerte es lo que la mayoría de la gente podría estar pensando cuando escuchan AI: alguna inteligencia omnisciente divina como Skynet o Hal 9000 que es capaz de razonamiento general e inteligencia humana mientras supera las capacidades humanas.
Las IA débiles son algoritmos altamente especializados diseñados para responder preguntas específicas y útiles en dominios de problemas estrechamente definidos. AUn programa de juego de ajedrez realmente bueno, por ejemplo, se ajusta a esta categoría. Lo mismo ocurre con el software que es realmente preciso en el ajuste primas de seguros. Estas configuraciones de IA son impresionantes a su manera pero muy limitado en general.
Otras lecturas
DeepMind AI necesita solo 4 horas de auto entrenamiento para convertirse en un ajedrez señor
Hollywood aparte, hoy no estamos cerca de una IA fuerte. En este momento, toda la IA es una IA débil, y la mayoría de los investigadores en el campo de acuerdo en que las técnicas que hemos ideado para hacer realmente genial Las IA débiles probablemente no nos llevarán a una IA fuerte.
Entonces, la IA actualmente representa más un término de marketing que un uno técnico La razón por la cual las compañías están promocionando sus “IA” como en oposición a la “automatización” es porque quieren invocar la imagen de las IA de Hollywood en la mente del público. Pero … eso no es Completamente mal. Si somos amables, las empresas simplemente pueden ser tratando de decir eso, aunque no estamos cerca de una IA fuerte, el Las IA débiles de hoy son considerablemente más capaces que las de solo Hace unos pocos años.
Dejando a un lado cualquier instinto de marketing, eso es realmente cierto. En cierto áreas, de hecho, ha habido un fuerte cambio en la capacidad de máquinas, y eso se debe en gran parte a las otras dos palabras de moda que usted escuchar mucho: aprendizaje automático y aprendizaje profundo.
 Agrandar / Un fotograma de un breve video Los ingenieros de Facebook publicaron que demonstrated real-time AI recognition of cat pictures (aka the holygrial para Internet) .Facebook
Agrandar / Un fotograma de un breve video Los ingenieros de Facebook publicaron que demonstrated real-time AI recognition of cat pictures (aka the holygrial para Internet) .Facebook Aprendizaje automático
El aprendizaje automático es una forma particular de crear máquina inteligencia. Supongamos que desea lanzar un cohete y predecir a dónde irá Esto es, en el gran esquema de las cosas, no que difícil: la gravedad se entiende bastante bien y puedes escribir el ecuaciones y averiguar a dónde irá en función de algunas variables como velocidad y posición inicial.
Pero esto se vuelve difícil de manejar cuando estás mirando algo donde las reglas no son tan claras y conocidas. Digamos que quieres una computadora para mirar fotos y quieres saber si alguna de ellas muestra un foto de un gato �Cómo se escriben las reglas para describir qué todas las combinaciones posibles de bigotes y orejas de gato se parecen a todos los ángulos posibles?
Otras lecturas
“OK Facebook”: ¿por qué detenerse en los asistentes? Facebook tiene más grandioso ambiciones para la IA moderna
El enfoque de aprendizaje automático ya es conocido: en lugar de tratando de escribir las reglas, construyes un sistema que puede calcular fuera de su propio conjunto de reglas internalizadas después de mostrar muchas ejemplos En lugar de tratar de describir gatos, simplemente mostrarías tu IA muchas fotos de gatos y deja que descubra qué es y No es un gato.
Esto es perfecto para nuestro mundo actual. Un sistema que aprende su Las propias reglas de los datos se pueden mejorar con más datos. Y si hay una cosa en la que nos hemos vuelto muy buenos como especie, es generar, almacenar y administrar una gran cantidad de datos. Quiero ser mejor en reconocer gatos? Internet está generando millones de ejemplos mientras hablamos.
La marea cada vez mayor de datos es una parte de por qué la máquina los algoritmos de aprendizaje han estado explotando. La otra parte tiene que hacer con cómo usar los datos.
Con el aprendizaje automático, además de los datos hay otros dos, preguntas relacionadas:
- �Cómo recuerdo lo que aprendí? En una computadora, ¿cómo puedo almacenar y representar las relaciones y reglas que extraje de los datos de ejemplo?
- �Cómo hago el aprendizaje? �Cómo modifico la representación? �He almacenado en respuesta a nuevos ejemplos y mejorar?
En otras palabras, ¿qué es lo que realmente está haciendo aprendiendo de todos estos datos?
En el aprendizaje automático, la representación computacional de la aprender que almacena se llama modelo. del modelo que utilizas tiene enormes efectos: determina cómo tu IA aprende, de qué tipo de datos puede aprender y de qué tipo de datos preguntas que puedes hacerle.
Echemos un vistazo a un ejemplo realmente simple para ver a qué me refiero. Digamos que estamos comprando higos en la tienda de comestibles, y queremos hacer una IA de aprendizaje automático que nos diga cuándo están maduros. Esta debería ser bastante fácil, porque con los higos es básicamente el más suave son, cuanto más dulces son.
Podríamos elegir algunas muestras de frutas maduras e inmaduras, ver cómo son dulces, luego póngalos en un gráfico y ajuste una línea. Esta La línea es nuestro modelo.
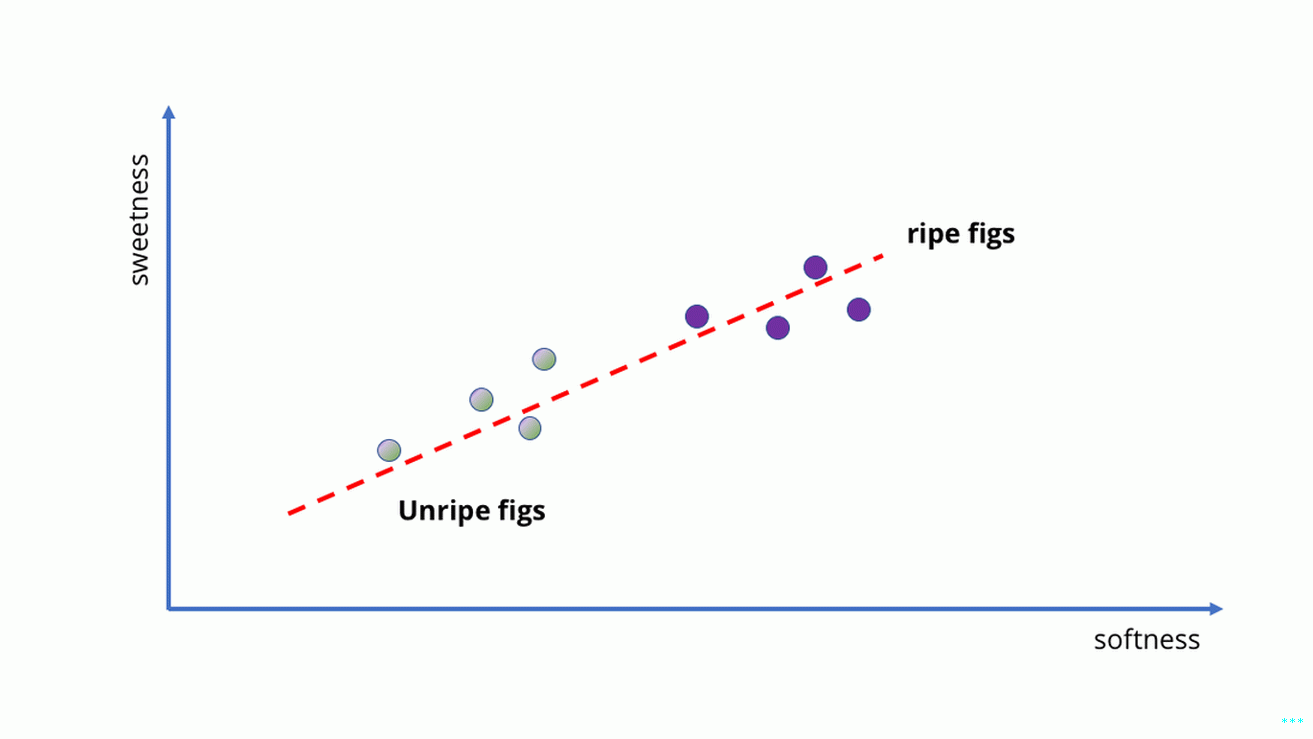
Nuestro bebé AI, en forma de línea. “Cuanto más suave es, más dulce es …” Haomiao Huang
Las cosas se vuelven más complicadas rápidamente cuando agrega datos adicionales, aunque. Haomiao Huang
�Mira eso! La línea captura implícitamente la idea de “la más suave es, más dulce es “sin que tengamos que escribirlo abajo. Nuestro bebé AI no sabe nada sobre el contenido de azúcar o cómo las frutas maduran, pero puede predecir cuán dulce será una fruta apretándolo
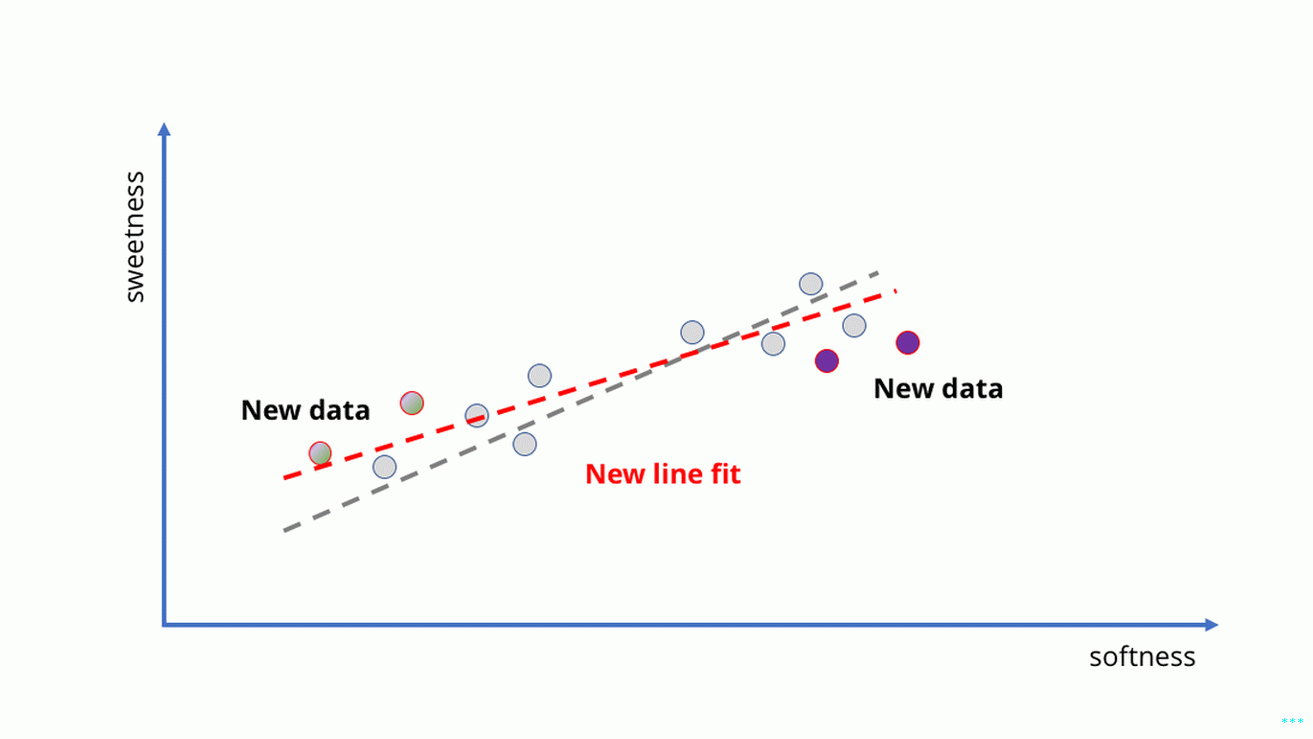
�Cómo entrenamos nuestro modelo para mejorarlo? Podemos recoger algunos más muestras y hacer otro ajuste de línea para obtener más precisión predicciones (como hicimos en la segunda imagen de arriba).
Los problemas se hacen evidentes de inmediato. Hemos estado entrenando nuestro higo Inteligencia artificial en buenos higos hasta ahora, pero ¿qué pasa si tiramos? en un huerto de higos? De repente, no solo hay fruta madura, También hay fruta podrida. Son súper suaves, pero son Definitivamente no es bueno para comer.
qué hacemos? Bueno, es un modelo de aprendizaje automático, por lo que podemos solo alimente nuevos datos, ¿verdad?
Como muestra la primera imagen a continuación, en este caso obtendríamos un Resultado completamente sin sentido. Una línea simplemente no es una buena manera de captura lo que sucede cuando la fruta está muy madura. Nuestro modelo ya no se ajusta a la estructura subyacente de los datos.
En cambio, tenemos que hacer un cambio y usar un mejor y más complejo modelo: tal vez una parábola o algo similar encaja bien. Ese el ajuste hace que el entrenamiento se vuelva más complicado, porque la adaptación estas curvas requieren matemáticas más complicadas que ajustar un línea.

OK, tal vez una línea no era una buena idea para una IA compleja … Haomiao Huang
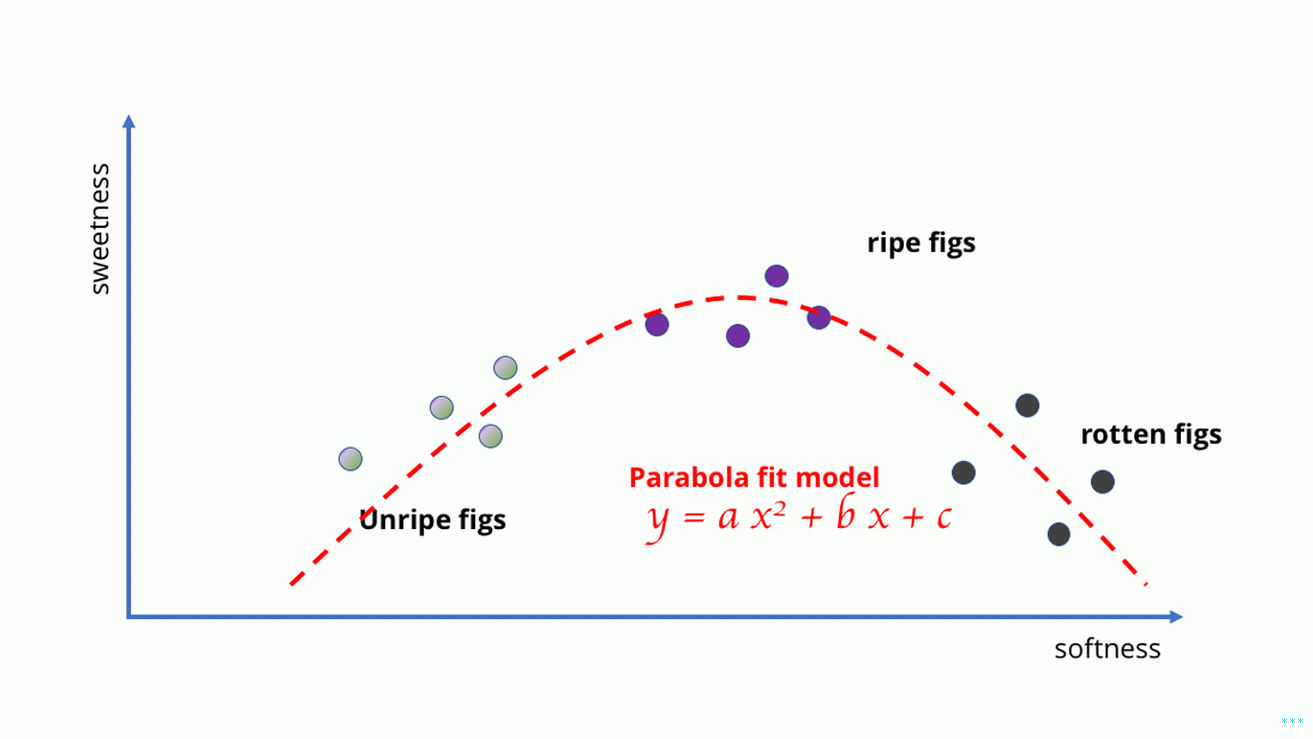
Matemáticas más complicadas ahora requeridas. Haomiao Huang
Este es un ejemplo bastante tonto, pero te muestra cómo el tipo de El modelo que elija determina el aprendizaje que puede hacer. Con higos, el los datos son simples, por lo que sus modelos pueden ser simples. Pero si lo intentas Para aprender algo más complejo, necesita modelos más complejos. Sólo ya que ninguna cantidad de datos permitiría que el modelo de ajuste de línea capture cómo la fruta podrida se comporta, no hay forma de hacer una curva simple que se ajuste a un montón de imágenes y obtener un algoritmo de visión por computadora.
El desafío del aprendizaje automático, entonces, es crear y elegir los modelos correctos para los problemas correctos. Necesitamos un modelo que es lo suficientemente sofisticado como para capturar realmente complicado relaciones y estructura pero lo suficientemente simple como para trabajar con él y entrenarlo. Entonces, aunque Internet, teléfonos inteligentes, etc. hemos hecho enormes cantidades de datos disponibles para entrenar, nosotros Todavía necesitamos los modelos correctos para aprovechar esta información.
Y ahí es precisamente donde entra el aprendizaje profundo.





