 Agrandar / Uno la voz se amplifica, la otra se silencia.
Agrandar / Uno la voz se amplifica, la otra se silencia.
Los investigadores de Google han desarrollado un sistema de aprendizaje profundo diseñado para ayudar a las computadoras a identificar y aislar mejor a las personas voces dentro de un ambiente ruidoso.
Como se señaló en una publicación en el Blog de Google Research de la compañía, esto semana, un equipo dentro del gigante tecnológico intentó replicar el efecto de cóctel, o la capacidad del cerebro humano para concentrarse en uno fuente de audio mientras filtra otros, tal como lo haría mientras hablando con un amigo en una fiesta.
El método de Google utiliza un modelo audiovisual, por lo que es principalmente enfocado en aislar voces en videos. La empresa ha publicado un número. de videos de YouTube que muestran la tecnología en acción:
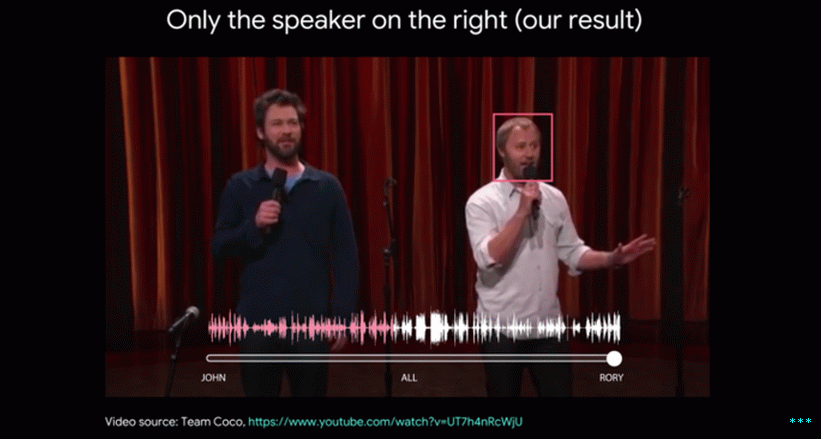
Buscando escuchar: Stand-up Looking to Listen: Sportsdebate
La compañía dice que esta tecnología funciona en videos con un solo audio rastrea y puede aislar voces en un video algorítmicamente, dependiendo sobre quién está hablando o haciendo que un usuario seleccione manualmente la cara de la persona cuya voz quieren escuchar.
Google dice que el componente visual aquí es clave, ya que la tecnología vigila cuando la boca de una persona se mueve para identificar mejor en qué voces enfocarse en un punto dado y crear más pistas de discurso individuales precisas para la duración de un video.
Según la publicación del blog, los investigadores desarrollaron este modelo al reunir 100,000 videos de “conferencias y charlas” en YouTube, extraer segmentos de esos videos de casi 2,000 horas presentando un discurso sin obstáculos, luego mezclando ese audio para crear un “cóctel sintético” con ruido de fondo artificial adicional.
Google luego entrenó a la tecnología para dividir ese audio mezclado por leer las “miniaturas de rostros” de las personas que hablan en cada video marco y un espectrograma de la banda sonora de ese video. El sistema es capaz de resolver qué fuente de audio pertenece a qué cara en un tiempo dado y crear pistas de voz separadas para cada hablante. Uf.
Buscando escuchar: Video conferencing Looking to Listen: Noisycafetería
Google destacó los sistemas de subtítulos como un área donde este sistema podría ser una bendición, pero la compañía dice que prevé “un amplia gama de aplicaciones para esta tecnología “y que es “actualmente explorando oportunidades para incorporarlo en varios productos de Google “. Hangouts y YouTube parecen dos fáciles lugares para comenzar No es difícil ver cómo podría funcionar la tecnología cuando aplicado a un par de anteojos inteligentes, a la manera de Google Glass, y auriculares con amplificador de voz, tampoco.
Otras lecturas
Revisión de Pixel Buds: OK Google, vuelve al dibujo del auricular Ayudar a los altavoces inteligentes como Google Home en su capacidad de reconocer voces individuales parece otro caso de uso, pero Debido a que este modelo está enfocado en video, probablemente funcionaría mejor con un altavoz con pantalla, como el Echo Show de Amazon. Más temprano este año, Google abrió el Asistente de Google para “pantalla inteligente” dispositivos como el Echo Show, pero la compañía no ha lanzado uno mismo.
En cualquier caso, las ramificaciones de privacidad de este tipo de tecnología parecen tan obvio como los posibles casos de uso. La voz de Google el aislamiento está lejos de ser a prueba de balas en los ejemplos anteriores, pero con un poco más de ajuste, podría ser un espionaje poderoso y herramienta de vigilancia en las manos equivocadas.
Sin embargo, eso es mucha especulación por ahora. Aquí espero esto la investigación al menos disminuye la necesidad de gritar en Google Home en el futuro.





